Lumosql has an extensive SQLite benchmarking suite which logs to an SQLite database (of course) and which has a reporting tool that can also merge results from multiple users or runs. We did many thousands of benchmark runs to produce this document, and we show the query commands we used to get each reported result. If you want to contribute some benchmarking runs get in touch and we can amalgamate the data.
This document only discusses results which compare the storage backends LumoSQL supports: SQLite's native B-tree, the LMDB
0.9.x backend, and the independent LMDB v1.0 backend, which adds optional page encryption and page checksums. These are timing results from the benchmark make
target. There is also the test-sql make target, which is about correctness and not part of this document.
Overall, this timing benchmark shows LMDB ahead on keyed access, random access, appends, reads, and bulk delete/replace, while the native SQLite B-tree stays ahead on in-place unindexed updates and small schema operations.
The R code for this plot is in the same directory so you can reproduce this image yourself.
Benchmarks metadata
These results are from a dataset created 22nd June 2026, with 900 benchmarking runs, all at SQLite 3.53.1, across ten data sizes covering the native backend, lmdb-0.9.35, and lmdbv1-1.0. The lmdbv1 runs cover all the main variables: rowsum, encryption, and page checksums. Unless stated otherwise the cited numbers are at datasize 10, comparing whole-test medians over the runs in each cell. To reproduce these numbers from the data yourself:
DB=./lumo-3.53.native-vs-lmdbv1.sqlite # from https://lumosql.org/benchmark-data; there may be a later one
# total runs
tclsh tool/benchmark-filter.tcl -db $DB -count
# SQLite version span (this dataset is 3.53.1 only)
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by sqlite-version
# data sizes present (ten: 2 3 4 5 6 8 10 15 20 30)
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by option-datasize
# backends present (native, lmdb-0.9.35, lmdbv1-1.0)
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by backend
Benchmark comparisons
Each command does an A/B comparison and prints a per-test speedup column. A speedup of less than 1.0 means group A is faster while greater than 1.0 means B is faster.
lmdbv1 is faster for reads, bulk inserts, and delete/replace
Taking the median across all ten data sizes, indexed SELECTs run about 13x faster on lmdbv1 than native, bulk row movement such as "a big INSERT after a big DELETE" about 7.5x, INSERT-from-SELECT about 6x, DROP TABLE about 5.7x, unindexed DELETE about 5x, plain INSERTs about 3x, indexed UPDATEs about 2.9x, and the transient-database test about 2.4x. Unindexed and string scans are 2 to 3.5x faster. The bulk-movement wins are largest at small data sizes and narrow as the data grows; the per-size range is in the table below.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -option rowsum-off -option lmdbv1_encrypt-off -option lmdbv1_checksum-off \
-B -no-backend -version 3.53.1 -option rowsum-off
Native wins on unindexed updates and small schema operations
Native beats lmdbv1 at updating rows in place without an index: unindexed UPDATEs about 1.7x faster on native (test 9), and the read-to-write transaction upgrade about 1.6x (test 3). Native is also ahead on the small schema operations — creating the database and tables about 2.1x, creating an index about 1.2x — and level on bulk transactional INSERTs (test 4) and indexed text UPDATEs (test 11). The same command as above shows it: read the tests where SPEEDUP exceeds 1.0.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -option rowsum-off -option lmdbv1_encrypt-off -option lmdbv1_checksum-off \
-B -no-backend -version 3.53.1 -option rowsum-off
Encryption most affects bulk writes and deletes
With the lmdbv1 backend page encryption is mostly a bit slower. At datasize 10 it adds about 80 to 110 percent on the bulk delete/replace operations (DELETE with an index 2.1x, DELETE without an index 1.9x, INSERT-from-SELECT 1.8x, a big INSERT after a big DELETE 1.8x), about 20 percent on plain INSERTs and indexed UPDATEs, and 10 to 16 percent on the read tests. Sequential and transactional INSERTs (test 4) and unindexed UPDATEs are about the same speed as unencrypted.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -datasize 10 -option lmdbv1_encrypt-on -option lmdbv1_checksum-off \
-B -backend lmdbv1 -version 3.53.1 -datasize 10 -option lmdbv1_encrypt-off -option lmdbv1_checksum-off
Page checksums slower on indexed reads, mostly unchanged elsewhere
Page checksums add about 40 percent to indexed SELECTs (test 8, 1.39x) and about 20 percent to unindexed DELETE (1.22x). Everything else is roughly the same.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -datasize 10 -option lmdbv1_checksum-on -option lmdbv1_encrypt-off \
-B -backend lmdbv1 -version 3.53.1 -datasize 10 -option lmdbv1_checksum-off -option lmdbv1_encrypt-off
LMDB v1.0 matches or modestly beats 0.9.x
At equal settings (rowsum, encryption, and checksum all off), lmdbv1-1.0 is level with lmdb-0.9.35 on reads and scans and faster on bulk movement... INSERT-from-SELECT about 0.50x, DELETE with an index 0.51x, unindexed DELETE 0.52x, a big INSERT after a big DELETE 0.59x, creating an index 0.63x, indexed and text UPDATEs about 0.78x. This suggests that choosing v1.0 doesn't have any negatives, and adds the encryption and checksum features.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -datasize 10 -option rowsum-off -option lmdbv1_encrypt-off -option lmdbv1_checksum-off \
-B -backend lmdb -version 3.53.1 -datasize 10 -option rowsum-off
Rowsum is slower for row-by-row work
Row checksums (rowsum) are computed per row touched, so the more rows visited the more overhead there is. On the native backend at datasize 10, bulk transactional INSERTs
are almost the same speed (1.15x) while unindexed UPDATEs are 4.2x slower. The read-only to read-write transaction upgrade is about 4.0x, indexed DELETE about 1.9x, unindexed scans
about 1.8x, and INSERT-from-SELECT about 1.7x.
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -no-backend -version 3.53.1 -datasize 10 -option rowsum-on \
-B -no-backend -version 3.53.1 -datasize 10 -option rowsum-off
Rowsum only appears slower on LMDB scans than on native scans
On the LMDB backend an unindexed SELECT with rowsum on is about 2.8x slower than with rowsum off, versus about 1.8x on native. This is worse than it looks, because LMDB's faster scan baseline makes the added per-row hashing a larger multiple. Unindexed UPDATEs cost about 3.0x on LMDB. lmdbv1-1.0 is much the same as 0.9.35 in this respect.
LMDB 0.9.35:
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdb -version 3.53.1 -datasize 10 -option rowsum-on \
-B -backend lmdb -version 3.53.1 -datasize 10 -option rowsum-off
LMDB v1.0:
tclsh tool/benchmark-filter.tcl -db $DB \
-compare -A -backend lmdbv1 -version 3.53.1 -datasize 10 -option rowsum-on -option lmdbv1_encrypt-off -option lmdbv1_checksum-off \
-B -backend lmdbv1 -version 3.53.1 -datasize 10 -option rowsum-off -option lmdbv1_encrypt-off -option lmdbv1_checksum-off
Why these differences exist
Keyed and random access favour LMDB. A single lookup or a short keyed range is a focused root-to-leaf descent. LMDB's pages are memory-mapped, so that
descent walks already-mapped memory with no page-cache layer in between, which is why point reads and indexed access are so much faster. count(*) is a special
case: LMDB answers it from its per-subdatabase entry count without walking any rows, whereas the native backend has to scan.
Large sequential scans favour native. LMDB re-walks the node structure on every row visit, while a native SQLite page is packed with everything the scan needs in place. This is a property of the LMDB data structure: native wins on an unindexed full-table scan.
Writes are slower on LMDB by design. LMDB is copy-on-write: a write touches and copies pages rather than updating them in place. The cost of that copying falls on writes, and most heavily on operations that dirty many small pages, such as an in-place unindexed UPDATE. (Copy-on-write is also what underlies LMDB's
crash safety and lock-free concurrent reads, though those properties are outside what this timing benchmark measures.) There is one important exception. For an
append (a monotonic-rowid insert, the common bulk-load and log-append pattern) SQLite passes a BTREE_APPEND hint, and the LumoSQL btree.c shim turns that into
LMDB's MDB_APPEND to skip the insert-position search, so appends avoid the penalty. This is why bulk transactional INSERTs (test 4) sit at parity with native
while in-place unindexed UPDATEs do not.
One operation that looks like a read but writes. Reads never invoke copy-on-write, with a single exception: the optimistic read-to-write transaction upgrade, where a statement begins reading and then writes, promoting its read transaction to a write transaction. That promotion incurs the copy-on-write cost, which is why the transaction-upgrade test groups with the writes in the table above.
Where rowsum sits. The experimental row checksum is applied above the storage backend, so the backend never sees it; the cost is the per-row hashing itself.
That is why rowsum's relative cost is larger on LMDB than on native — the faster LMDB baseline makes the same added work a larger multiple — even though the
backend plays no direct part in computing it. Note that rowsum is per-row, and is distinct from both the SQLite checksum VFS (per-page) and the lmdbv1 page
checksum (also per-page).
Detail
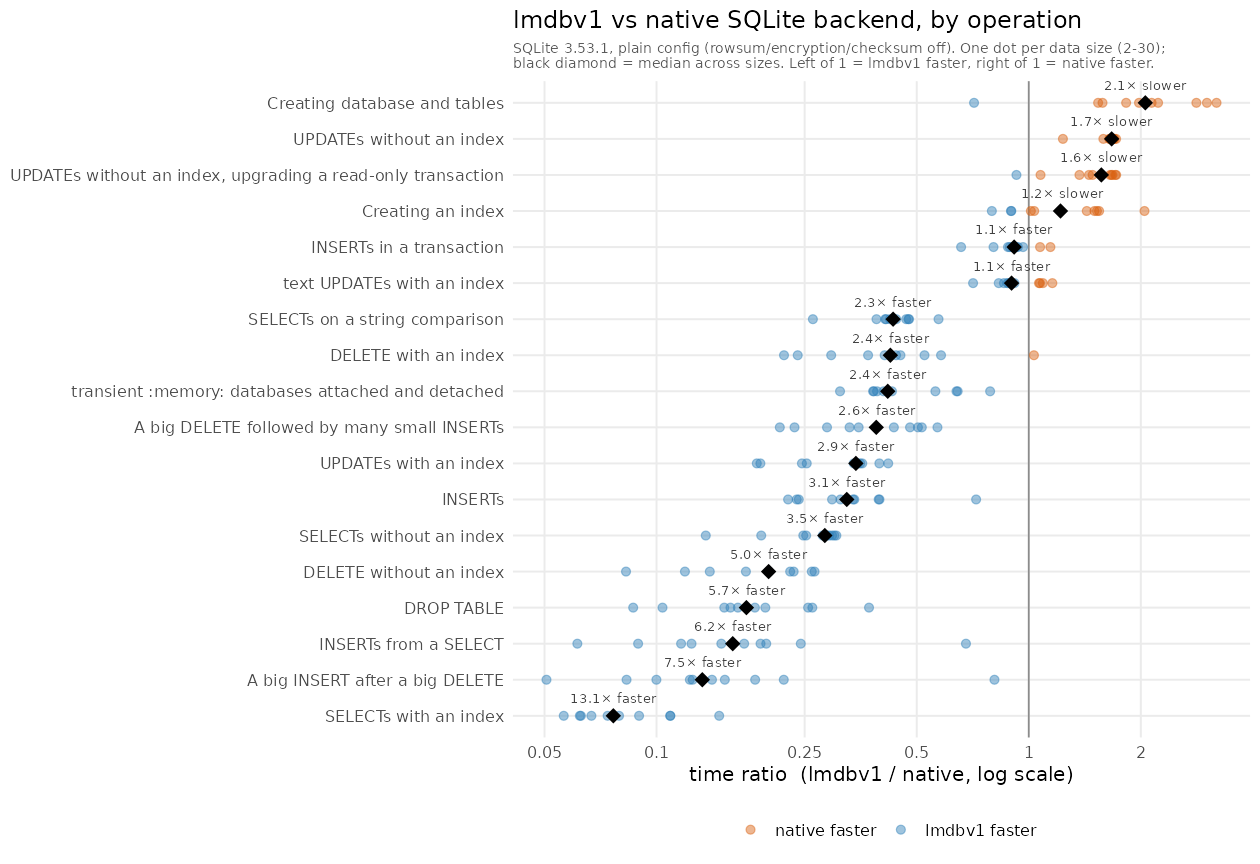
lmdbv1 versus native, by operation
This table compares lmdbv1-1.0 (A) against native (B) at SQLite 3.53.1, rowsum off, encryption off, checksum off. The SPEEDUP is lmdbv1 time divided by native time, so 0.08x means lmdbv1 takes 8 percent of native's time, and the reciprocal names the multiple (1 / 0.08 = ~13x).
The figure is the median of the per-test ratio across all ten data sizes (2, 3, 4, 5, 6, 8, 10, 15, 20, 30). The min and max columns give the range of that ratio
across the ten sizes. The chart lmdbv1-vs-native-allsizes.png plots every data size as a point with this median as a diamond, and the script
lmdbv1-vs-native-chart.R regenerates both from benchmarks.sqlite.
| Test | Operation | SPEEDUP (median, all sizes) | min | max | Faster by |
|---|---|---|---|---|---|
| 8 | SELECTs with an index | 0.08x | 0.06x | 0.15x | lmdbv1 ~13x |
| 15 | A big INSERT after a big DELETE | 0.13x | 0.05x | 0.81x | lmdbv1 ~7.5x |
| 12 | INSERTs from a SELECT | 0.16x | 0.06x | 0.68x | lmdbv1 ~6x |
| 17 | DROP TABLE | 0.17x | 0.09x | 0.37x | lmdbv1 ~5.7x |
| 13 | DELETE without an index | 0.20x | 0.08x | 0.27x | lmdbv1 ~5x |
| 5 | SELECTs without an index | 0.28x | 0.14x | 0.30x | lmdbv1 ~3.5x |
| 2 | INSERTs | 0.32x | 0.23x | 0.72x | lmdbv1 ~3x |
| 10 | UPDATEs with an index | 0.34x | 0.19x | 0.42x | lmdbv1 ~2.9x |
| 16 | A big DELETE followed by many small INSERTs | 0.39x | 0.21x | 0.57x | lmdbv1 ~2.6x |
| 18 | transient :memory: databases attached and detached | 0.42x | 0.31x | 0.79x | lmdbv1 ~2.4x |
| 14 | DELETE with an index | 0.43x | 0.22x | 1.03x | lmdbv1 ~2.4x |
| 6 | SELECTs on a string comparison | 0.43x | 0.26x | 0.57x | lmdbv1 ~2.3x |
| 11 | text UPDATEs with an index | 0.90x | 0.71x | 1.16x | lmdbv1 ~1.1x |
| 4 | INSERTs in a transaction | 0.91x | 0.66x | 1.14x | lmdbv1 ~1.1x |
| 7 | Creating an index | 1.23x | 0.80x | 2.05x | native ~1.2x |
| 3 | UPDATEs without an index, upgrading a read-only transaction | 1.57x | 0.93x | 1.72x | native ~1.6x |
| 9 | UPDATEs without an index | 1.67x | 1.24x | 1.72x | native ~1.7x |
| 1 | Creating database and tables | 2.06x | 0.71x | 3.20x | native ~2.1x |
The ranking by median differs from any single data size. DROP TABLE is lmdbv1's largest win at datasize 10 (0.07x) but sits mid-table on the all-sizes median (0.17x), its ratio ranging from 0.09x to 0.37x. Indexed SELECT (test 8) ranges only 0.06x to 0.15x. The min and max columns show this spread per operation: the bulk-movement operations (INSERT after DELETE, INSERT-from-SELECT, creating tables) vary several-fold across data sizes, while the indexed-read, unindexed-DELETE, and unindexed-UPDATE results are stable across the range.
Test 18 (transient :memory: databases attached and detached) exercises the temp-environment path: each attach opens a transient LMDB environment, which the
backend now serves from a small pool of reused unsynced environments rather than creating and destroying one per attach. lmdbv1 is about 2.4x faster than native
here.
To list what a database contains before comparing (distinct values and run counts per dimension):
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by backend
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by backend-version
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by sqlite-version
tclsh tool/benchmark-filter.tcl -db $DB -stats -group-by option-datasize