LumoSQL
LumoSQL is a modification (not a fork) of the SQLite embedded data storage library, which is among the most-deployed software. We are currently in Phase II of the project.
If you are reading this on GitHub you are looking at a read-only mirror. The master is always available at lumosql.org. LumoSQL adds security, privacy, performance and measurement features to SQLite.
Benchmarking
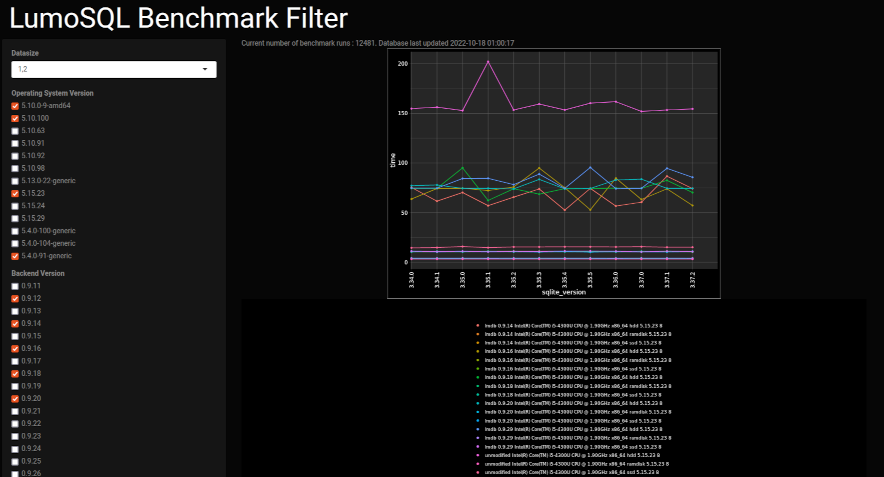
SQLite can test and compare results consistently across many kinds of system and configurations using the Not-forking tool. Example:
Pluggable backends
LumoSQL can swap back end key-value store engines in and out of SQLite. LMDB is the most famous (but not the only) example of an alternative key-value store, and LumoSQL can combine dozes of versions of LMDB and SQLite source code like this:
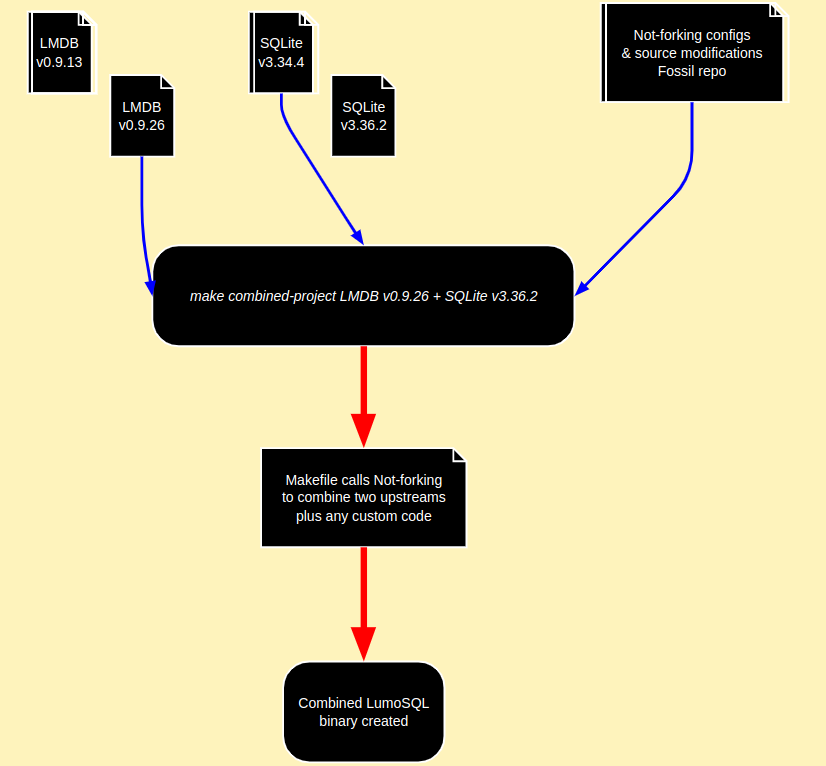
In LumoSQL 0.4 there are three LumoSQL backends:
- the default SQLite Btree storage system
- LMDB
- the ancient Berkley Database
We are looking at some interesting new development in key-value storage to add and benchmark.
Encryption and corruption detection, optionally per-row
LumoSQL adds modern encryption to SQLite, including Attribute-Based Encryption (ABE). This can be done on a per-row basis, and also includes per-row checksums so that any error can be noticed quickly and located down to the individual row. Per-row checksums also make some search and comparison operations much faster.
Organised and Supported
LumoSQL is distributed under very liberal MIT licence terms.
LumoSQL is supported by the NLNet Foundation.
LumoSQL runs on x86, ARM-32 and RISC-V architectures, and many Linux and BSD OSs.
Table of Contents
- Design, Not-Forking and Participating
- LumoSQL, and SQLite's Billions of Users
- Limitations of LumoSQL
- Build Environment and Dependencies
- Using the Build and Benchmark System
- A Brief History of LumoSQL
Design, Not-Forking and Participating
If you are reading this on Github, then you are looking at a mirror. LumoSQL is is maintained using the Fossil repository. If you want to participate in LumoSQL there is a forum, and if you have code contributions you can ask for access to the respository.
LumoSQL has multiple upstreams, but does not fork any of them despite needing modifications. The novel Not-forking tool semi-automatically tracks upstream changes and is a requirement for building LumoSQL. Between not-forking and the LumoSQL Build and Benchmark System, LumoSQL is as much about combining and configuring upstreams as it is about creating original database software. By maintaining Not-forking outside LumoSQL, we hope other projects will find it useful.
The LumoSQL and SQLite projects are cooperating, so any merge friction is expected to become less over time, and key to that is the approach of not forking.
LumoSQL, and SQLite's Billions of Users
LumoSQL exists to demonstrate changes to SQLite that might be useful, but which SQLite probably cannot consider for many years because of SQLite's unique position of being used by a majority of the world's population.
SQLite is used by thousands of software projects, just three being Google's Android, Mozilla's Firefox and Apple's iOS which between them have billions of users. That is a main reason why SQLite is so careful and conservative with all changes.
On the other hand, many of these same users need SQLite to have new features which do not fit with the SQLite project's cautious approach, and LumoSQL is a demonstration of some of these improvements.
The LumoSQL documentation project reviews dozens of relevant codebases. SQLite has become ubiquitous over two decades, which means there is a great deal of preparation needed when considering architectural changes.
Limitations of LumoSQL
As of LumoSQL 0.4, there are many obvious limitations, including:
- The tests used in benchmarking mostly come from an ancient version of SQLite's speedtest.tcl modified many times, to which DATASIZE and DEBUG have been added. Experts in SQLite and LMDB database testing should review the files in not-fork.d/sqlite3/benchmark/*test. There are 9 tools named *speed* in the SQLite source, and any/all of them should be added here.
- Neither LMDB nor BDB backends ship with latest SQLite builds. Now all the LumoSQL infrastructure exists, that is a smaller, more maintainable and repeatable task. But it is not done yet. There are some generic problems to be solved in the process, such as the optimal way to address keysize disparities between a KVP store provider and SQLite's internal large keysize.
- If we import more of the speed tests from SQLite identified above, then we will have a problem with several LMDB and at least two BDB instances, where the SQLite tests will fail. In most cases this is about the LMDB port needing to be more complete but in some it is about relevance, where some SQLite tests will not apply. In addition some backends will always need to have additional tests (for example, BDB has more extensive user management than SQLite).
Build Environment and Dependencies
Most developers already have the required minimum of git and core unix-style development tools. SQLite has very few dependencies (mostly Tcl), and LumoSQL adds one Perl-based processing tool.
LumoSQL is mirrored to Github and application developers can use git with Github in the usual way. LumoSQL developers working on the LumoSQL library internals choose to use Fossil source code manager instead of git, and if you're planning to develop LumoSQL internals then you need Fossil.
There are many reasons why people choose Fossil. For LumoSQL one of them is that SQLite and Fossil are symbiotic projects, each written in the other.
Debian or Ubuntu-derived Operating Systems
Uncomment existing deb-src line in /etc/apt/sources.list, for example
for Ubuntu 20.04.2 a valid line is:
deb-src http://gb.archive.ubuntu.com/ubuntu focal main restricted
Then run
sudo apt update # this fetches the deb-src updates
sudo apt full-upgrade # this gets the latest OS updates
sudo apt install git build-essential tclx
sudo apt build-dep sqlite3
The exact commands above have been tested on a pristine install of Ubuntu 20.04.2 LTS, as installed from ISO or one of the operating systems shipped with Windows Services for Linux.
Fedora-derived Operating Systems
On any reasonably recent Fedora-derived Linux distribution, including Red Hat:
sudo dnf install --assumeyes \
git make gcc ncurses-devel readline-devel glibc-devel autoconf tcl-devel tclx-devel
Common to all Linux Operating Systems
Once you have done the setup specific to your operating system in the previous steps, the following should work on reaonably recent Debian and Fedora-related operating systems, and Gentoo.
Other required tools can be installed from your operating system's standard packages. Here are the tool dependencies:
- Mandatory: the not-forking tool, which is a Perl script that needs to be downloaded and installed manually. The instructions for not-forking are on its website.
- Recommended: Fossil. As described above, you don't necessarily need Fossil. But Fossil is very easy to install: if you can't get version 2.13 or later from your distrbution then it is easy to build from source.
(Note! Ubuntu 20.04, Debian Buster and Gentoo do not include a sufficiently modern Fossil, while NetBSD
and Ubuntu 20.10 do.) Since you now have a development environment anyway you can
build Fossil trunk according to the official instructions or this simpler version (tested on Ubuntu 20.04 LTS):
- wget -O- https://fossil-scm.org/home/tarball/trunk/Fossil-trunk.tar.gz | tar -zxf -
- sudo apt install libssl-dev
- cd Fossil-trunk ; ./configure ; make
- sudo make install
- For completeness (although every modern Linux/Unix includes these), to build and benchmark any of the Oracle Berkeley DB targets, you need either "curl" or "wget", and also "file", "gzip" and GNU "tar". Just about any version of these will be sufficient, even on Windows.
- If you are running inside a fresh Docker or similar container system, Fossil may be confused about the user id. One solution is to add a user (eg "adduser lumosql" and answer the questions) and then "export USER=lumosql".
The not-forking tool will advise you with a message if you need a tool or a version that is not installed.
On Debian 10 "Buster" Stable Release, the not-forking makefile ("perl Makefile.PL") will warn that git needs to be version 2.22 or higher. Buster has version 2.20, however this is not a critical error. If you don't like error messages scrolling past during a build, then install a more recent git from Buster backports.
Quickstart: Using the Build and Benchmark System
This is a very brief quickstart, for full detail see the Build and Benchmark System documentation.
Now you have the dependencies installed, clone the LumoSQL repository using
fossil clone https://lumosql.org/src/lumosql , which will create a new subdirectory called lumosql and
a file called lumosql.fossil in the current directory.
Try:
cd lumosql
make what
To see what the default sources and options are. The what target does not make any changes although it may generate a file Makefile.options to help make parse the command line.
Benchmarking a single binary should take no longer than 4 minutes to complete depending
on hardware. The results are stored in an SQLite database stored in the LumoSQL
top-level directory by default, that is, the directory you just created using fossil clone.
Start by building and benchmarking the official SQLite release version 3.35.5, which is the current release at the time of writing this README.
make benchmark USE_LMDB=no USE_BDB=no SQLITE_VERSIONS='3.35.5'
All source files fetched are cached in ~/.cache/LumoSQL in a way that maximises reuse regardless of
their origin (Fossil, git, wget etc) and which minimises errors. The LumoSQL build system is driving the
not-fork tool, which maintains the cache. Not-fork will download just the differences of a remote
version if most of the code is already in cache.
The output from this make command will be lots of build messages followed by something like this:
*** Running benchmark 3.35.5
TITLE = sqlite 3.35.5
SQLITE_ID = 1b256d97b553a9611efca188a3d995a2fff71275
SQLITE_NAME = 3.35.5 2021-04-19 18:32:05 1b256d97b553a9611efca188a3d995a2fff712759044ba480f9a0c9e98faalt1
DATASIZE = 1
DEBUG = off
LMDB_DEBUG = off
LMDB_FIXED_ROWID = off
LMDB_TRANSACTION = optimistic
ROWSUM = off
ROWSUM_ALGORITHM = sha3_256
SQLITE3_JOURNAL = default
RUN_ID = 70EA47101F68CDD6D3C0ED255962A2AA50F1540EE4FEBB46A03FAD888B49676C
OK 0.003 1 Creating database and tables
OK 0.019 2 1000 INSERTs
OK 0.007 3 100 UPDATEs without an index, upgrading a read-only transaction
OK 0.052 4 25000 INSERTs in a transaction
OK 0.113 5 100 SELECTs without an index
OK 0.243 6 100 SELECTs on a string comparison
OK 0.012 7 Creating an index
OK 0.046 8 5000 SELECTs with an index
OK 0.036 9 1000 UPDATEs without an index
OK 0.113 10 25000 UPDATEs with an index
OK 0.093 11 25000 text UPDATEs with an index
OK 0.032 12 INSERTs from a SELECT
OK 0.020 13 DELETE without an index
OK 0.028 14 DELETE with an index
OK 0.027 15 A big INSERT after a big DELETE
OK 0.010 16 A big DELETE followed by many small INSERTs
OK 0.005 17 DROP TABLE
0.859 (total time)
A database with the default name of benchmarks.sqlite has been created with
two tables containing the results. This is one single test run, and the test
run data is kept in the table test_data. The table run_data contains data
relative to a set of runs (version numbers, time test started, etc). This is cumulative,
so another invocation of make benchmark will append to benchmarks.sqlite.
Every run is assigned a SHA3 hash, which helps in making results persistent over time and across the internet.
The tool benchmark-filter.tcl does some basic processing of these results:
tool/benchmark-filter.tcl
RUN_ID TARGET DATE TIME DURATION
70EA47101F68CDD6D3C0ED255962A2AA50F1540EE4FEBB46A03FAD888B49676C 3.35.5 2021-05-20 16:13:18 0.859
The option DATASIZE=parameter is a multiplication factor on the size of the chunks that is used for benchmarking. This is useful because it can affect the time it takes to run the tests by a very different multiplication factor:
make benchmark USE_LMDB=no USE_BDB=no DATASIZE=2 SQLITE_VERSIONS='3.35.5 3.33.0'
followed by:
tool/benchmark-filter.tcl
RUN_ID TARGET DATE TIME DURATION
70EA47101F68CDD6D3C0ED255962A2AA50F1540EE4FEBB46A03FAD888B49676C 3.35.5 2021-05-20 16:13:18 0.859
65DD0759B133FF5DFBBD04C494F4631E013C64E475FC5AC06EC70F4E0333372F 3.35.5++datasize-2 2021-05-20 16:18:30 2.511
931B1489FC4477A41914A5E0AFDEF3927C306339FBB863B5FB4CF801C8F2F3D0 3.33.0++datasize-2 2021-05-20 16:18:51 2.572
Simplistically, these results suggest that SQLite version 3.35.5 is faster than 3.33.0 on larger data sizes, but that 3.35.5 is much faster with smaller data sizes. After adding more versions and running the benchmarking tool again, we would soon discover that SQLite 3.25.0 seems faster than 3.33.0, and other interesting things. Simplistic interpretations can be misleading :-)
This is a Quickstart, so for full detail you will need the Build/Benchmark documentation. However as a teaser, and since LMDB was the original inspiration for LumoSQL (see the History section below for more on that) here are some more things that can be done with the LMDB target:
$ make what LMDB_VERSIONS=all
tclsh tool/build.tcl what not-fork.d MAKE_COMMAND='make' LMDB_VERSIONS='all'
BENCHMARK_RUNS=1
COPY_DATABASES=
COPY_SQL=
MAKE_COMMAND=make
NOTFORK_COMMAND=not-fork
NOTFORK_ONLINE=0
NOTFORK_UPDATE=0
SQLITE_VERSIONS=3.35.5
USE_SQLITE=yes
USE_BDB=yes
SQLITE_FOR_BDB=
BDB_VERSIONS=
BDB_STANDALONE=18.1.32=3.18.2
USE_LMDB=yes
SQLITE_FOR_LMDB=3.35.5
LMDB_VERSIONS=all
LMDB_STANDALONE=
OPTION_DATASIZE=1
OPTION_DEBUG=off
OPTION_LMDB_DEBUG=off
OPTION_LMDB_FIXED_ROWID=off
OPTION_LMDB_TRANSACTION=optimistic
OPTION_ROWSUM=off
OPTION_ROWSUM_ALGORITHM=sha3_256
OPTION_SQLITE3_JOURNAL=default
BUILDS=
3.35.5
3.18.2
+bdb-18.1.32
3.35.5+lmdb-0.9.11
3.35.5+lmdb-0.9.12
3.35.5+lmdb-0.9.13
3.35.5+lmdb-0.9.14
3.35.5+lmdb-0.9.15
3.35.5+lmdb-0.9.16
3.35.5+lmdb-0.9.17
3.35.5+lmdb-0.9.18
3.35.5+lmdb-0.9.19
3.35.5+lmdb-0.9.20
3.35.5+lmdb-0.9.21
3.35.5+lmdb-0.9.22
3.35.5+lmdb-0.9.23
3.35.5+lmdb-0.9.24
3.35.5+lmdb-0.9.25
3.35.5+lmdb-0.9.26
3.35.5+lmdb-0.9.27
3.35.5+lmdb-0.9.28
3.35.5+lmdb-0.9.29
TARGETS=
3.35.5
3.18.2
+bdb-18.1.32
3.35.5+lmdb-0.9.11
3.35.5+lmdb-0.9.12
3.35.5+lmdb-0.9.13
3.35.5+lmdb-0.9.14
3.35.5+lmdb-0.9.15
3.35.5+lmdb-0.9.16
3.35.5+lmdb-0.9.17
3.35.5+lmdb-0.9.18
3.35.5+lmdb-0.9.19
3.35.5+lmdb-0.9.20
3.35.5+lmdb-0.9.21
3.35.5+lmdb-0.9.22
3.35.5+lmdb-0.9.23
3.35.5+lmdb-0.9.24
3.35.5+lmdb-0.9.25
3.35.5+lmdb-0.9.26
3.35.5+lmdb-0.9.27
3.35.5+lmdb-0.9.28
3.35.5+lmdb-0.9.29
After executing this build with make benchmark rather than make what, here are summary results using a
a new parameter to benchmark-filter.tcl:
$ tool/benchmark-filter.tcl -fields TARGET,DURATION
TARGET DURATION
3.35.5 0.852
3.35.5+lmdb-0.9.11 1.201
3.35.5+lmdb-0.9.12 1.211
3.35.5+lmdb-0.9.13 1.212
3.35.5+lmdb-0.9.14 1.219
3.35.5+lmdb-0.9.15 1.193
3.35.5+lmdb-0.9.16 1.191
3.35.5+lmdb-0.9.17 1.213
3.35.5+lmdb-0.9.18 1.217
3.35.5+lmdb-0.9.19 1.209
3.35.5+lmdb-0.9.20 1.223
3.35.5+lmdb-0.9.21 1.229
3.35.5+lmdb-0.9.22 1.230
3.35.5+lmdb-0.9.23 1.215
3.35.5+lmdb-0.9.24 1.218
3.35.5+lmdb-0.9.25 1.219
3.35.5+lmdb-0.9.26 1.220
3.35.5+lmdb-0.9.27 1.220
3.35.5+lmdb-0.9.28 1.209
3.35.5+lmdb-0.9.29 1.209
Again, simplistic interpretations are insufficient, but the data here suggests that LMDB has decreased
in performance over time, to improve again with the most recent versions, and no version of LMDB is faster than native SQLite 3.35.5 . However, further
benchmark runs indicate that is not the final story, as LMDB run on slower hard disks improve in relative
speed rapidly. And using the DATASIZE option also changes the picture.
The results for the Berkely DB backend are also most interesting.
A Brief History of LumoSQL
There have been several implementations of new storage backends to SQLite, all of them hard forks and nearly all dead forks. A backend needs certain characteristics:
- btree-based key-value store
- transactions, or fully ACID
- full concurrency support, or fully MVCC
There are not many candidate key-value stores. One of the most widely-used is Howard Chu's LMDB. There was a lot of attention in 2013 when Howard released his proof of concept SQLite port. LMDB operates on a very different and more modern principle to all other widely-used key/value stores, potentially bringing benefits to some users of SQLite. In 2013, the ported SQLite gave significant performance benefits.
The original 2013 code modified the SQLite btree.c from version SQLite
version 3.7.17 to use LMDB 0.9.9 . It took considerable work for LumoSQL to
excavate the ancient code and reproduce the results.
By January 2020 the LumoSQL project concluded:
- Howard's 2013 performance work is reproducible
- SQLite's key-value store improved in performance since 2013, getting close to parity with LMDB by some measures
- SQLite can be readily modified to have multiple storage backends and still pass 'make test'
- SQLite doesn't expect there to be multiple backends, and this has many effects including for example in error handling. An abstraction layer was needed.
Since then, many new possibilities have emerged for LumoSQL, and new collaborations.